Model Compression
Introduction
Model compression refers to the practice of modifying model loading or storage to decrease resource usage and/or improve the latency for the model. For deep learning models, we should ask ourselves three basic questions:
- Disk space: How much hard disk space does the model consume?
- Memory usage: When the model is loaded into memory (RAM or GPU memory), how much memory is consumed?
- Latency: How long does it take to load the model into memory? After a model is loaded, how much time is required to perform inference on a sample or batch?
Baseline exercise
Before we dive into model compression techniques, let’s establish a baseline. We’ll load a RoBERTa transformer model available through Hugging Face. We’ll use the model to classify the first few sentences of my favorite book, Alice in Wonderland.
Throughout this exercise, we’ll use a neat memory profiler to track RAM consumption and runtime.
Types of compressions
- Serialization
- Quantization
- Pruning
Serialization
Serialization encodes a model in a format that can be stored on a disk and reloaded (deserialized) when it’s needed. If a model is serialized by using a common framework, serialization methods can also facilitate interoperability. So the model can be deployed by using a system that’s different from the development environment.
Torchscript Serialization
PyTorch provides native serialization by using TorchScript. Serialization takes two forms: scripting and tracing. During tracing, sample input is fed into the trained model and is followed (traced) through the model computation graph, which is then frozen. At the time of this writing, only tracing is supported for transformer models, so we’ll use this serialization method
Torchscript Profiler
ONNX Serialization
The most common serialization approach for deep learning models is the Open Neural Network Exchange (ONNX) format. Models that are saved by using the ONNX format can be run by using ONNX Runtime. ONNX Runtime also provides tools for model quantization, which we’ll explore in the next section.
ONNX Profiler
Compression
Through ONNX serialization, we’ve significantly reduced inference time. But we haven’t made much of a dent in model size and RAM usage. The techniques we’ll cover next will help reduce the memory footprint and hard disk footprint of large transformer models.
Quantization
Deep learning frameworks generally use floating point (32-bit precision) numbers. This system makes sense during training but might be unnecessary during inference. Quantization describes the process of converting floating point numbers to integers.
Dynamic Quantization
The easiest method of quantization PyTorch supports is called dynamic quantization. This involves not just converting the weights to int8 — as happens in all quantization variants — but also converting the activations to int8 on the fly, just before doing the computation (hence “dynamic”). The computations will thus be performed using efficient int8 matrix multiplication and convolution implementations, resulting in faster compute. However, the activations are read and written to memory in floating point format.
Static Quantization
One can further improve the performance (latency) by converting networks to use both integer arithmetic and int8 memory accesses. Static quantization performs the additional step of first feeding batches of data through the network and computing the resulting distributions of the different activations (specifically, this is done by inserting “observer” modules at different points that record these distributions). This information is used to determine how specifically the different activations should be quantized at inference time (a simple technique would be to simply divide the entire range of activations into 256 levels, but we support more sophisticated methods as well).
Quantization Aware Training
Quantization-aware training(QAT) is the third method, and the one that typically results in highest accuracy of these three. With QAT, all weights and activations are “fake quantized” during both the forward and backward passes of training: that is, float values are rounded to mimic int8 values, but all computations are still done with floating point numbers. Thus, all the weight adjustments during training are made while “aware” of the fact that the model will ultimately be quantized; after quantizing, therefore, this method usually yields higher accuracy than the other two methods.

In the case where accuracy can’t be achieved with static quantization
Both quantization methods reduce inference time compared to their larger counterparts. Additionally, hard disk space usage has been reduced by more than 50 percent.
Based on these results, quantization seems like a no-brainer: Why would you not do this? But before we decide to deploy a quantized model, we need to consider one more factor: how these changes affect the model predictions.
The general performance of the model appears relatively unaffected. But quantization has changed some of the predictions. In this situation, we should examine some of the examples that showed altered predictions before deploying the quantized model.
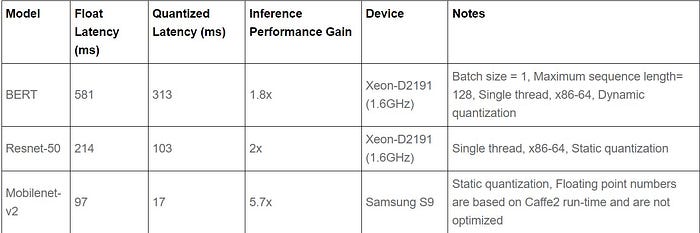
Quantization provides a 4x reduction in the model size and a speedup of 2x to 3x compared to floating point implementations depending on the hardware platform and the model being benchmarked. Some sample results are:
Pruning
Pruning refers to the practice of ignoring or discarding “unimportant” weights in a trained model. But how do you determine which weights are unimportant? Here are three methods that can identify unimportant weights:
Magnitude pruning
The magnitude pruning method identifies unimportant weights by considering their absolute values. Weights that have a low absolute value have little effect on the values that are passed through the model.
Magnitude pruning is mostly effective for models that are trained from scratch for a specific task because the values of the weights dictate importance for the task that the model was trained on. Oftentimes, you’ll want to use the weights from a trained model as a starting point and fine tune these weights for a specific dataset and task using a process known as transfer learning. In a transfer learning scenario, the values of the weights are also related to the task that’s used to pretrain the network. Magnitude pruning isn’t a good fit for scenarios that involve transfer learning.
Movement pruning
During movement pruning, weights that shrink in absolute value during training are discarded. This approach is well-suited for transfer learning because the movement of weights from large to small demonstrates that they were unimportant (actually, counterproductive) for the fine-tuning task.
In their 2020 paper, Movement Pruning: Adaptive Sparsity by Fine-Tuning, Sanh et al. demonstrated that movement pruning applied to a fine-tuned BERT model adapted better to the end task than magnitude pruning. Movement pruning yielded 95 percent of the original performance for natural language inference and question answering. It used only 5 percent of the encoder’s weight.
Pruning attention heads
One differentiating architectural feature of transformer models is the employment of multiple parallel attention “heads.” In their 2019 paper, Are Sixteen Heads Really Better than One?, Michel et al. showed that models trained by using many heads can be pruned at inference time to include only a subset of the attention heads without significantly affecting model metrics.
Let’s test the impact of pruning N percent of heads. Because we’re interested in measuring only resource usage, we’ll prune heads randomly. For a real-world application, however, you should prune heads based on their relative importance.
Put it all together
We’ve examined multiple methods individually for model compression. But you’ll probably want to combine techniques for the biggest impact. Based on our experience at this blog , most middle-of-the-road applications benefit from considering these techniques, in the following order:
- Use ONNX serialization.
- Additionally apply quantization by using ONNX.
- Additionally prune attention heads.
- Use other small architecture.
The following chart shows the results of applying these techniques sequentially.
The results show that ONNX serialization substantially decreased inference time without changing model predictions. Quantization decreased hard disk usage and further reduced inference time.
Conclusion
I hope you’ve found this guide both practical and useful for identifying where to start with model compression. This analysis focused mainly on CPU inference (the cheaper option). For nearly real-time inference, you might prefer to run inference on GPU-enabled instances.